一:源码介绍RDD
1.RDD介绍
五大特性,保证了Spark的扩展性,容错性等特性。
A list of partitions ====> 一个许多分区的集合,分区中包含数据
A function for computing each split ===> 为每个分区提供一个computing的函数
A list of dependencies on other RDDs ===> RDD会依赖其他RDDs, 这种特性叫做:lineage(生命线);特例:第一个RDD不依赖其他RDD,这个特性解决容错性 Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) Key-Value的RDD存在一个分区器,默认是Hash分区器;分区器的作用类型MR中的Partitioner,决定上一个RDD中的数据到下一个RDD的时候是在那个分区中 Optionally, a list of preferred locations to compute each split on (e.g. block locations foran HDFS file) 数据计算本地化操作,类似MR 
发现,分块后仍然是单独运算。
2.对应的五个方法

protected def getPartitions: Array[Partition]: ===> 获取当前RDD所有的分区
def compute(split: Partition, context: TaskContext): Iterator[T] ===> 对每个分区上的数据进行计算操作 protected def getDependencies: Seq[Dependency[_]]: ===> 获取依赖的RDD,依赖的RDD是一个集合 protected def getPreferredLocations(split: Partition): Seq[String] ===> 数据计算本地化专用 val partitioner: Option[Partitioner] ===> 获取分区器
二:扩张讲解
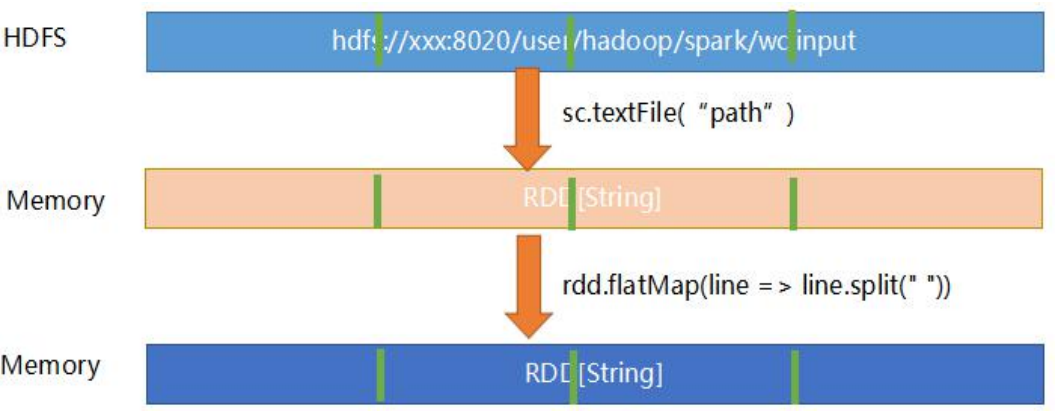
1.textFile
使用处:sc.textFile("path")
从源码中可以看到:
1.textFile函数返回的RDD最少2个分区,另一个是自己实现。
2.textFile底层调用hadoopFile函数 3.hadoopFile底层使用MapReduce旧的API读取给定path路径的数据(org.apache.hadoop.mapred.InputForamt) 4.读取HDFS文件返回的RDD具体类型是:HadoopRDD
2.hadoopRDD
关于textFile返回的RDD的讲解。
从源码中可以看到在hadoopRDD有许多函数,但是主要的函数还是下面的三个:
1.getPartitions: 使用InputFromat返回的InputSplit集合构建HadoopRDD的分区对象
2.compute:根据输入的HadoopRDD分区对象还原成为InputSplit对象,使用InputFormat的getRecordReader函数获取具体的数据读取器,并返回一个迭代器 3.getPreferredLocations:依据inputsplit对象的getLocations获取最优节点的hostname信息
3.MapPartitionsRDD
从源码中可以看到以下信息:
1.所有的参数/函数都依赖父RDD 例如:compute函数: 最终会调用第一个RDD的compute函数,这个函数依旧依赖父RDD
三:RDD创建
1.RDD构建
RDD的构建依赖于MapReduce的InputFormat类,默认使用旧的API
sc.hadoopRDD ===> 给定旧的API读取HDFS数据 sc.newAPIHadoopRDD ===> 给定使用新的InputFormat API读取HDFS上的数据
2.RDD的意思
弹性分布式数据集。
Resilient Distributed Dataset (RDD)
Spark中最基本的一个抽象
3.RDD创建方式(两种)
第一种方式:
作用:主要用于测试 序列化已经存在的一个scala的集合产生RDDval data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data) distData.map(v => (v%2,1)).reduceByKey(_+_).collect()
第二种方式
作用:生成环境中使用
读取存储在外部数据源中的数据并形成RDD返回val distFile = sc.textFile("data.txt")
官网说法:

四:RDD函数讲解与使用
1.RDD函数类型
Transformation(算子):(在Driver中执行)
执行策略是Lazy
从一个RDD产生一个新的RDD, RDD[T] ==> RDD[U] 当一个RDD调用transfromation类型的函数的时候,只是在内部构建了一个DAG的执行图(基于RDD的依赖),当RDD被触发的时候,DAG执行图开始执行 Action(算子): (在Executors中执行)立即执行。
当一个RDD产生的结果不是RDD的时候,认为是一个Action(动作), RDD[T] ==> OtherType
Action动作的执行会导致在transformation过程中构建的DAG图被执行(被提交到运行节点上去执行) Spark的job的提交运行最终由SparkContext中的runJob函数负责,会将RDD构建的DAG执行图进行一系列的划分,最终提交到Executors中执行任务
Persist:
不是立即执行的,但是unPersist是立即执行的。
将RDD中的数据进行持久化或者反持久化操作 持久化级别(StorageLevel):RDD默认是内存
2.persist的类型(StorageLevel类中)
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false) val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) val MEMORY_ONLY = new StorageLevel(false, true, false, true) val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) val OFF_HEAP = new StorageLevel(false, false, true, false)======>(分布式文件系统)
3.persist的方法
是lazy的,只有当有action被触发的时候,才会进行持久化操作;
RDD执行的时候,会从持久化的RDD中读取数据,不会重新执行父RDD的代码逻辑
cache:内部调用persist persist: 内部调用persist(MEMORY_ONLY) persist(StorageLevel): 给定级别进行RDD数据缓存,要求这个RDD没有进行过缓存 反持久化:立即执行的 unpersist: 删除持久化的数据 持久化: 当调用cache函数进行持久化操作的时候,如果内存不够,不会cache所有数据,只会cache一部分数据(按照分区进行cache的)
4.持久化的级别
持久化的级别一般选择为:
MEMORY_ONLY MEMORY_ONLY_SER MEMORY_AND_DISK除非数据不能丢失,而且计算过后,父RDD没法重新计算数据的,在RDD缓存的时候,才使用X2的级别
5.注意点
一般在RDD不使用的时候,要调用unpersist函数进行持久化的RDD删除
6.RDD API
map: 转换,按条进行数据转换
flatMap: 转换+结果扁平化 filter:过滤数据 mapPartitions:转换,按分区进行分区的数据转换 repartition:重置分区,内部调度coalesce coalesce:重置分区;当分区数量减少的时候,可以将参数shuffle设置为false,与上面的不同之处在于有shuffle参数 distinct:去重用 reduceByKey:按照key进行聚合,聚合后类型和RDD的V类型必须一样 aggregateByKey:按照key进行聚合,聚合后类型和RDD的V类型可以不一样 groupByKey:按照Key进行数据聚合,防止出现OOM异常 sortByKey: 按照key进行数据排序 zip: 拉链操作,将两个RDD合并 zipPartitions:zip底层实现,按照分区进行RDD的合并 zipWithIndex:RDD的数据和序列号进行拉链操作及合并 zipWithUniqueId:RDD和一个唯一的id进行拉链操作foreach: 对每条数据进行操作,一般不用
foreachPartition: 对每个分区的数据进行操作,常用 top:获取topN take:获取前多少个 saveXXXX: 将数据通过Hadoop的OutputFormat类进行数据输出
7.Transformation的API

8.action的API

五:spark快的原因
1.spark快的原因
SparkRDD不进行cache操作,后面的操作也比前面的操作快,原因是(第二次执行比第一次快):Spark对将job的执行缓存一段时间(缓存到磁盘/内存),当第二次执行的时候,会自动从磁盘/内存中获取,不需要重新执行父RDD的代码逻辑
2.RDD内部逻辑结构
除了可以从内部结构上看,也可以从源码中知道,会使用最近的盘计算。

